一个关键词 18 万 ! AI 搜索已经被这帮人玩坏了
一个关键词 18 万 ! AI 搜索已经被这帮人玩坏了昨天晚上闲着没事,想在 DeepSeek 搜一下 AI 博主有哪些可以学习的。 结果没想到,搜索结果里竟然出现了我自己。 内心 OS:祖坟冒青烟了,妈妈我出息了,我被 AI 认证了,以后简历可以写被
来自主题: AI资讯
10420 点击 2025-10-22 10:10
 搜索
搜索
昨天晚上闲着没事,想在 DeepSeek 搜一下 AI 博主有哪些可以学习的。 结果没想到,搜索结果里竟然出现了我自己。 内心 OS:祖坟冒青烟了,妈妈我出息了,我被 AI 认证了,以后简历可以写被

刚刚,DeepSeek 推出了全新的视觉文本压缩模型 DeepSeek-OCR。 该模型最大的突破在于极高的压缩效率: 20 个节点每天可处理 3300 万页数据,硬件要求仅为 A100-40G。

家人们,就在国庆放假前的今天凌晨,那个总在节前“搞事”的 DeepSeek,又双叒叕深夜悄然上线了!讲真,DeepSeek 是真的不考虑我们媒体人的死活啊哈哈!每次都卡着放假前更新,之前大家都转发的吐槽截图,本人又翻出来了:
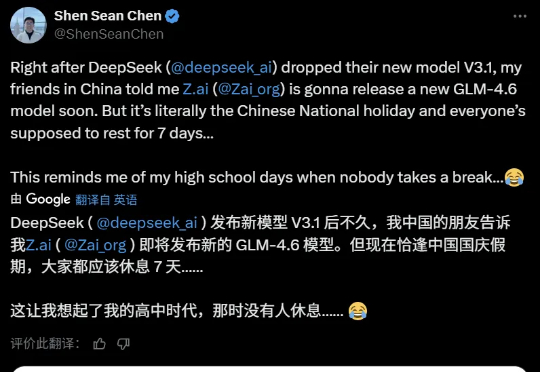
昨天,深度求索刚刚开源 DeepSeek-V3.2-Exp。今天,另一国产大模型之光智谱 AI 也正式发布了旗下新一代旗舰模型 GLM-4.6,刚好撞车 Claude Sonnet 4.5。但有一点不同,智谱的 GLM-4.6 会继续开源,它即将上线 Hugging Face、ModelScope 等平台,遵循 MIT 协议。

在今年 3 月 DeepSeek 和豆包占领国内产品月活用户增速前两名的时候,以第三姿态紧随其后的,是红果短剧。两者之间这个巧合的「偶遇」,意外也不意外。反映的正是我们当下经历的最重要的技术与文化浪潮。
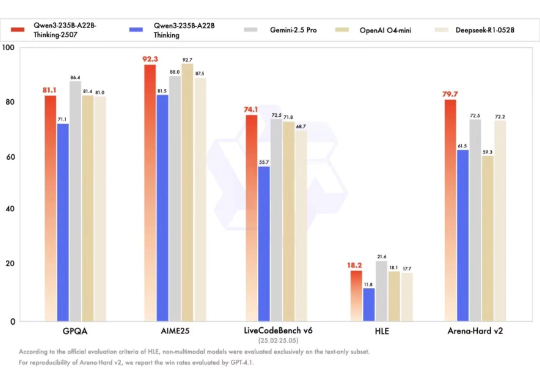
2025 年 9 月 19 日,亚马逊云科技官宣:Qwen3 和 DeepSeek v3.1,首次上线 Amazon Bedrock ,正式对外提供服务,再一次引起了全球生成式 AI 市场对 Amazon Bedrock 这一产品的关注。

用过才知道,「快」不是万能药。
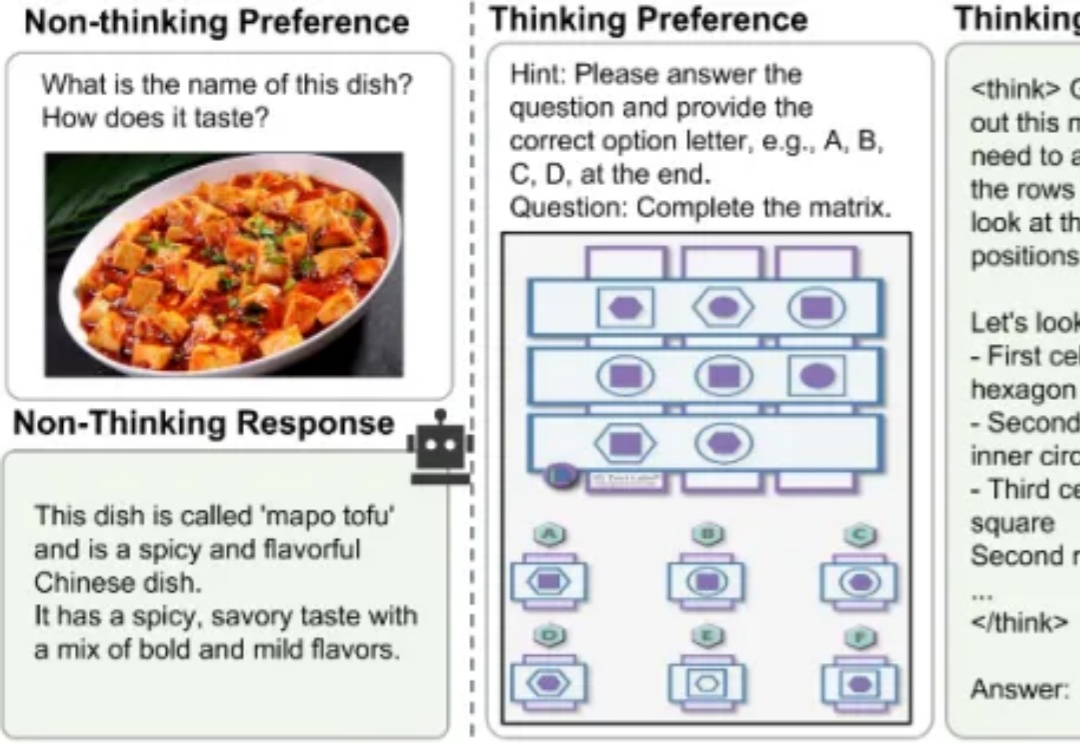
当前,业界顶尖的大模型正竞相挑战“过度思考”的难题,即无论问题简单与否,它们都采用 “always-on thinking” 的详细推理模式。无论是像 DeepSeek-V3.1 这种依赖混合推理架构提供需用户“手动”介入的快慢思考切换,还是如 GPT-5 那样通过依赖庞大而高成本的“专家路由”机制提供的自适应思考切换。
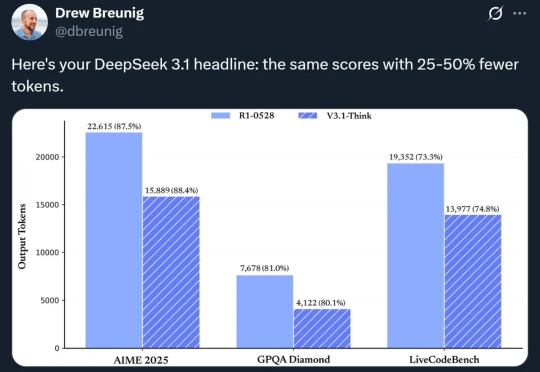
在最近的一档脱口秀节目中,演员张俊调侃 DeepSeek 是一款非常「内耗」的 AI,连个「1 加 1 等于几」都要斟酌半天。
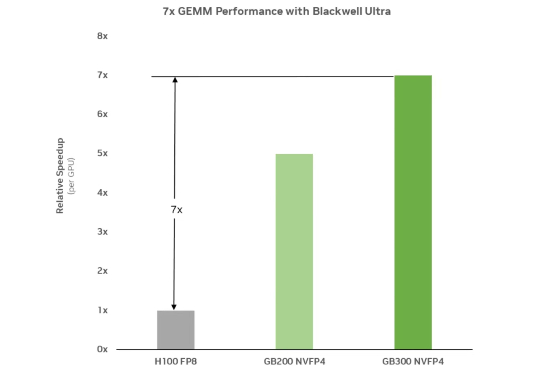
前些天,DeepSeek 在发布 DeepSeek V3.1 的文章评论区中,提及了 UE8M0 FP8 的量化设计,声称是针对即将发布的下一代国产芯片设计。